
When College Board published the initial PSAT concordance in PSAT/NMSQT Understanding Scores 2015 in January 2016, it labeled the tables “preliminary.” It appears that they are on the verge of publishing the “final” version. Word was that it would arrive on June 3, but the College Board website has not been updated. A reader interested in the impact on National Merit cutoffs was kind enough to send along an advance copy last week. This analysis is based on that copy. Should the final version prove different, I will publish an update as soon as possible.
The new document is not a Rosetta stone for National Merit Semifinalist cutoffs for the class of 2017. In fact, it does a poorer job in comparing scores at the top percentiles than did the January concordance. Had the May version been released with PSAT scores, it would have set cutoff expectations far too high. [The concordances are not used by NMSC to determine cutoffs; they are only useful for making estimates.] If you are expecting to glean new information about NMSF cutoffs from the latest document, I’d urge you to resume your regularly scheduled work. If you want to dive into some of the ways of interpreting the new data and ways in which the conflicting PSAT and SAT concordances are at odds, please read on.
Understanding (May update) is notable in what did not change. All of the percentile information is the same as that released in January. Frankly, there was no expectation that College Board would update the percentiles. It has said that it intends to stick with the research study percentiles for both the PSAT and SAT. When October 2016 PSAT results are returned, College Board will include true October 2015 percentiles. Until that time, PSAT percentiles are flawed and should be treated as nothing more than gross indicators. The reported standard error of measurement has gone up modestly in the latest version of Understanding (from 42 points to 46 points on total score).
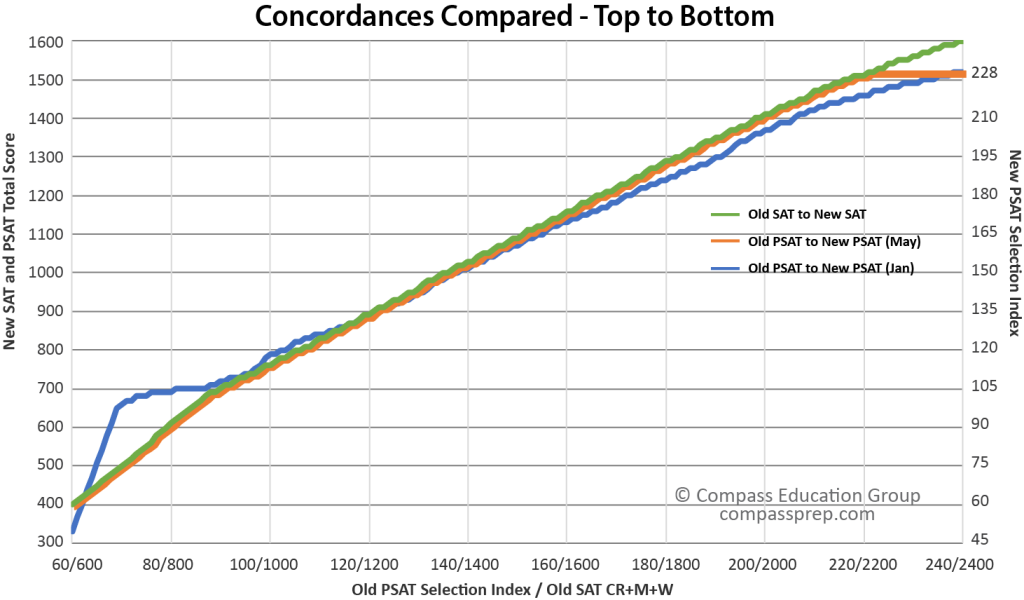
It quickly became obvious that the updated concordance tables are not the result of a separate, in-depth equipercentile concordance of old PSAT and new PSAT. Rather, they represent the new SAT concordances lopped off at end of the PSAT score ranges. This is true for test scores, section scores, and Selection Index. Below is the concordance of the 60 to 240 Selection Index scores (600 to 2400 CR+M+W SAT scores) to new PSAT and SAT scores. Note that the green and orange lines — PSAT (May update) and SAT — follow the exact same path until the PSAT hits a wall at its maximum score of 1520.
A note on comparing total scores and Selection Index.
One difficulty in using National Merit data to judge the accuracy of the concordances is that there is no concordance of old Selection Index to new Selection Index. Instead, we must substitute the concordance of the old Selection Index to the new total score. Because the Selection Index weights the verbal component at twice the math component, the split matters. A 1440 made up of 720 EBRW and 720 Math has a new Selection Index of 216. A 1440 made up of 680 EBRW and 760 Math has a Selection Index of 212. The good news is that the gap between verbal and math scores has narrowed with the new test. On average, in fact, EBRW scores are higher on the PSAT than the Math scores. This is unprecedented. At the upper tail, though, we still see more high Math scores. For the convenience of presenting the information graphically, we will assume that EBRW and Math are split evenly.
A note on the challenge of test scales and edge cases.
Measuring student performance across a wide score range is a challenging task. Test makers try to avoid overly long exams, but they must present enough questions at appropriate difficulty levels to accomplish their goals. Sometimes, a score range promises more than it can deliver. Even though the PSAT covered easier material than the SAT and was a shorter test, a perfect score on a section was still an 80 and a perfect test a 240. Correcting this scale overreach is one of the reasons why it made sense to reconsider PSAT scoring and establish it on a 160-760 range (48-228 Selection Index).
To some degree, scores are stretched or truncated on virtually every standardized test with fixed endpoints. A perfect raw score on a harder SAT form might actually equate to an 820 were the scale allowed to run free. Instead, it is truncated at 800. Without the demand of a fixed endpoint, a perfect raw score on an easier form might be more accurately presented as a 780. It must be stretched to an 800. The artifacts of this kneading can be seen when looking at the raw-to-scaled score tables of the old PSAT. There was often a precipitous drop-off in score with the first missed question or two or three. These drops are the tell-tale signs of a scale that has been stretched to the breaking point.
| Raw Score | Math | Writing |
|---|---|---|
| 39 | 80 | |
| 38 | 80 | 78 |
| 37 | 76 | 73 |
| 36 | 73 | 72 |
| 35 | 71 | 70 |
| 34 | 69 | 68 |
| 33 | 68 | 65 |
The new PSAT concordance dead ends just when things are getting really interesting on the SAT. A 1520 on the new SAT is concordant with a 2210 on the old. A 1600 compares to a 2390. Over that 80 point range, the concordant values increase by 180 points — the steepest rise across the entire scale. I find this rapid rise — likely due to the “stretching” that often occurs near the endpoints of a score range — about as unlikely as the hard cap the PSAT runs into at 1520 / 221.
The wild ride of the blue line at the low end of the range is an example of what can happen when data is thin or when scores are forced to fit specific endpoints. The concordance lurches upward because few students achieve the lowest scores on the new PSAT. The lack of a guessing penalty means that even modestly test savvy students can score in the 500s with ease. The May version implies a much smoother roll-on. It’s hard to know which version is right. Given the scoring rules of the new test, the quick-off-the-line nature of the January concordance seems far more likely. Without more technical information, it’s not clear that the lower ranges should have even been reported. Inappropriately compared scores can be worse than no comparison at all. This is why you will not see an ACT to SAT concordance go below an 11 ACT Composite. College Board, in contrast, accounts for every point value along the new and old score ranges in its old-to-redesigned concordances.

“In evaluating the results of an equipercentile concordance, it is vital to note that the equipercentile function does not directly take into account the number of observations at individual score points. [Concordance] results might be unstable at score points where very few examinees score, even though we might have a very large sample size overall.”
Mary Pommerich, “Concordance: The Good, the Bad, and the Ugly.” Linking and Aligning Scores and Scales. Neil Dorans, Mary Pommerich & Paul Holland (Eds.). (2007).
How well do the concordances match the actual data?
The SAT concordance has far more long-term import than the PSAT/NMSQT concordance, but the latter has the advantage of an entire cohort having already taken the exam. The SAT will not be in the same situation until spring 2017. College Board has released little actual PSAT data (most is from sample studies), but a number of critical points have leaked out.
The high end of the score range has the greatest import for National Merit purposes. This also means that we can flip things around and use what we know about National Merit and the National Hispanic Recognition Program to assess the accuracy of the concordance versions.
Some of the problems faced are familiar. Given that any new PSAT or SAT concordance was derived from pilot studies of modest sizes and questionable provenance, it’s not surprising that there would be questions about the alignment of low and high scores. The edge cases are particularly impacted by low sample sizes. When looking at the case of National Merit Semifinalists, it seems unlikely that College Board was able to sufficiently sample the population. NMSF cutoffs in the most competitive states are nothing if not edge cases. Even the heartiest of sample sizes starts to go grow thin as scores approach 223, 224, or 225 on the new PSAT.
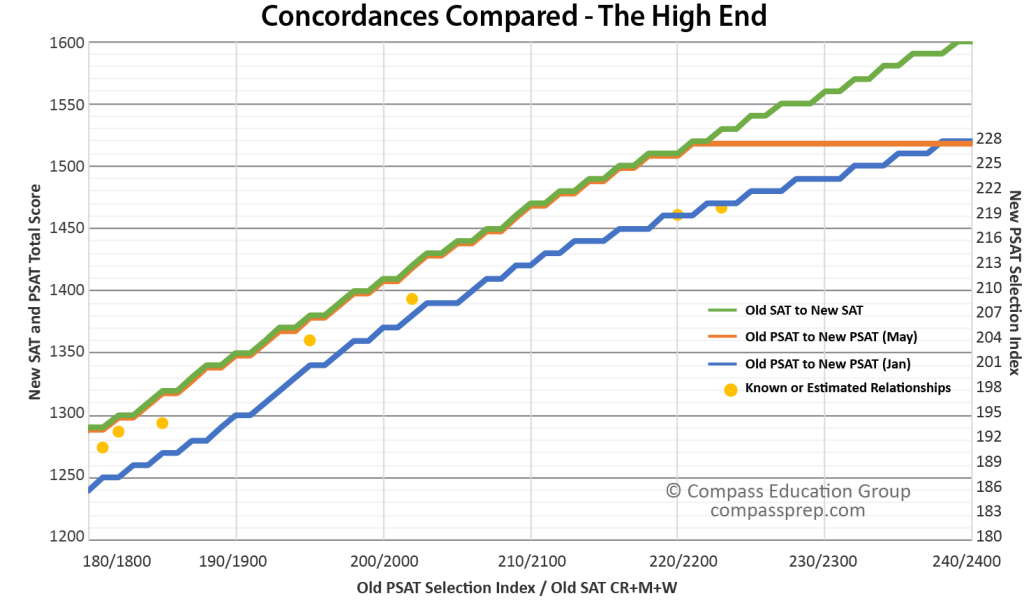
For Selection Index scores in the 180 – 200 range on the old PSAT, the May concordance performs similarly to or better than the January concordance. As scores increase, however, the two concordances diverge. Hitched to the SAT concordance, the May version does not behave well as it approaches the top of the PSAT range. A critical point is the Commended level for National Merit because it reflects a very similar group of students year-to-year. For the October 2014 test (class of 2016), the cutoff was 202. For the October 2015 test (class of 2017), the cutoff is 209. The January concordance (blue) would have predicted a new cutoff of approximately 207. The May concordance would imply a cutoff of 213. Advantage January. Still higher up the scale, partial data in Texas and California suggest National Merit Semifinalist cutoffs for the class of 2017 in the 218-220 and 219-221 range for those states (which had cutoffs of 220 and 223 for the class of 2016). The January concordance fits well with these estimates. The May final concordance would “predict” NMSF cutoffs of 226 and 228 for Texas and California. These figures are comically out of tune with actual results.
If the newer concordance were to be believed, students with perfect scores would take all of the National Merit Semifinalist spots in New Jersey, Massachusetts, California, Virginia, Maryland, and District of Columbia. Another seven states would have Semifinalists with 1500 total scores (approximately 225 Selection Index) or higher. These results are not correct. The new concordance overestimates — probably by several hundred percent — the number of students receiving perfect scores, for example.
How different are the January and May PSAT concordances?
| New PSAT Total Score | Old PSAT SI Jan Concordance | Old PSAT SI May Concordance | Difference |
|---|---|---|---|
| 1520 | 239 | 221 | 18 |
| 1500 | 233 | 217 | 16 |
| 1480 | 226 | 213 | 13 |
| 1460 | 220 | 209 | 11 |
| 1440 | 214 | 206 | 8 |
| 1420 | 209 | 202 | 7 |
| 1400 | 206 | 199 | 7 |
| 1300 | 191 | 182 | 9 |
| 1200 | 172 | 167 | 5 |
| 1100 | 154 | 151 | 3 |
| 1000 | 138 | 136 | 2 |
The table above uses the old PSAT Selection Index as a measuring stick to show how the difference between the two concordances grows at the high end of the score range. Compass research shows that the earlier concordance is more trustworthy in this range.
Nothing is Real
What confuses many interpreters is the assumption that the May concordance — being “final” — is based on actual PSAT results. This is far from the case. No College Board concordance for the new PSAT or SAT is based on operational data! There are a number of sound, practical reasons for this. For concordance results to be useful, they must be generalizable. Strong concordances such as the old SAT to ACT linkage are built on large numbers of students taking tests at similar times under similar, operational conditions. March SAT students do not fit this mold because they are not representative of the full cohort of the class of 2017. Those testers also having recent old SAT scores would be an even less apt group. There would also be a strong bias given the fact that the new SAT would, in all cases, have been taken after the old SAT.
Similarly, no students were taking operational old and new PSATs in a way that would meet the appropriate conditions. Instead, College Board had to create study samples that it hoped would model overall results. In some cases this involved convincing schools to offer sample tests to their students outside of the actual test dates. In other cases, this involved paying college students to take tests. It’s not hard to imagine the logistical and statistical challenges involved in these sorts of studies.
Yet College Board seemed to do a good job with this in the January concordance. Where it has taken a wrong turn is in letting the SAT concordance drive the bus. The old PSAT is not the old SAT. The new PSAT is not the new SAT. The concordances should be based on the conditions specific to each exam.
In the big picture, a PSAT concordance has a limited audience. Although useful for school districts and states for longitudinal research, concordant PSAT scores will not be used by any college for admission purposes. National Merit Scholarship Corporation has no need of a concordance in determining cutoffs. By the time next year’s scores come out, virtually no sophomore or junior will have old PSAT scores in need of comparison. Nor is it mission critical for College Board that PSAT scores be directly comparable to ACT scores. All of this points to why — once the SAT concordance was ready — the PSAT concordance would be swallowed up whole. It was as much a political decision as a psychometric one. Were College Board to leave the PSAT concordance independent of the SAT concordance, there would be ongoing confusion about which concordance was definitive. A polite way of describing the PSAT concordance is “aspirational.” It conforms with the most desirable outcome, not necessarily the most accurate one.
“Since the redesigned PSAT/NMSQT is scaled to the redesigned SAT, some small adjustments to the PSAT/NMSQT concordance may be necessary once the scaling of the redesigned SAT is final in March 2016.”
–College Board Guide to Concordance, October 2015
![]()
The College Board quote above seems like a reasonable hedge about PSAT results. The problem is that it makes little logical sense. In order to distinguish the new, vertical scale established in May, let me abbreviate it as scale-VM. No PSAT/NMSQT has ever been given or scored under scale-VM. The October 2015 PSAT was created and graded prior to scale-VM. The January concordance was created prior to scale-VM. The old SAT was obviously created before scale-VM. Every single data point was fixed before the scale-VM was “finalized.” One of the points of a concordance is that it avoids concerns over scales. College Board didn’t have to worry about what grading standards or scaling were used by ACT during their joint concordance study in 2005 because student scores determined the results. The notion of using scale-VM as the basis of a PSAT concordance is a political fiction. It does not fit the actual data; it merely clarifies which concordance College Board has chosen as its future.
Why such a fuss over a conversion table?
My research started with the simple mission of seeing what information the new concordance might provide about National Merit scores. I was asked a question about the new tables, and I sought an answer. As I dug deeper, though, I grew uncomfortable with the way the new concordance was being presented.

Nice article Art! Glad you were able to make good use of the report.
And from your first graph, I think I finally understand what you mean when you say that they are forcing the SAT concordance table on to the PSAT. But if you think about it, it makes sense. I think an underlying claim that college board makes is that your score on the PSAT predicts your score on the SAT. 1 to 1. (Maybe with a slight rise due to time.) Given that claim, if you have a 1:1 conversion from old PSAT to old SAT, and a 1:1 conversion from new PSAT to new SAT, then really there’s only room for a single concordance table.
I guess we think (hope!) that the SAT concordance table is accurate – it seems like it will be actively used in college admissions, so it better. If that concordance table doesn’t match the actual PSAT results (which as you point out it clearly doesn’t), then the likely conclusion is that the 1:1 targeted correspondence between new PSAT and new SAT didn’t hold. Oops.
To summarize: the new PSAT scores were inflated compared to the old PSAT, while the new SAT scores were a little inflated (but not as much) compared to the old SAT. This means that the new PSAT scores overestimated what you will score on the SAT. But CB didn’t admit that. Presumably in future years it will be back in line…
Absolutely right about the alignment claims that CB is trying to make. I just don’t believe the necessary assumptions to be true. I’ve taken to thinking of the October 2015 as the predesigned PSAT, if you will. Not old enough to be old; not new enough to be new. The first and last of its kind.
If we accept the notion that the concordance tells us where the PSAT should be (in the future, at least), then I believe we’d need to conclude that the October 2015 PSAT was under-inflated at the high end. In other words, to make the real world agree with the concordances, there would need to be a lot more 222-228s out there. Alas, they’re slowly painting themselves into a concordant corner.
I do hope that we can attribute much of this to the unique challenge of the 2015 PSAT and that the SAT concordance holds true. What I find so frustrating is that College Board has no checks. If it sticks to schedule, it won’t have to release new SAT data until late summer of next year. Colleges should use the new concordance tables — what alternative is better for students? — but I hope that they bring more pressure to bear on College Board to publish its research.
Thank you again for the information.
Art, thank you for this much-needed post! Wow – those May tables really only confuse the issue! Whatever a 1520 may concord to on an “SAT-equivalent” basis, it definitely concords to a 240 (or thereabouts) on the old PSAT. Anything called a “PSAT concordance table” really needs to include that reality.
Question: Since the new PSAT score is supposed to show how you would have scored that day on the SAT, why can’t students just make use of the SAT concordance tables? The May PSAT tables are really just SAT tables anyway – does College Board believe that students and families don’t know how to divide by 10?
Liz,
Good question. Given recent events, College Board is not in a position to cast aspersions on anyone’s math abilities. Some of it boils down to i dotting. States and districts need a point-by-point concordance to translate their historical data, so College Board is providing the exact table it wants them to use. Whichever way the scores are translated, they really should be backed up by more research than College Board has provided.
Can a PSAT score have different “index scores” depending on which state one lives in?
Mo,
No, a given set of Reading & Writing and Math scores mean the same thing everywhere. What does vary is the score level required to become a Semifinalist. You may want to see our National Merit Cutoff post or FAQ for more details.